I’d like to present a brief lesson in contemporary linguistic research with the goal of showing that we live in a marvelous age of quick and ready research tools freely available to even the most humble of internet users. Hence, a little effort goes a long way. My point is that when we make claims about language usage (and by "we" I mostly mean those of us who present our claims about language to the public via the interwebz) we need not make such claims based on our intuitions and emotions; rather, we can perform a little due diligence in a way that linguistic pontificators of the past simply could not. And bully for us.
My subject for today’s
Full Liberman is this classic example of language mavenry from Prospect magazine:
Words that think for us by Edward Skidelsky, lecturer in philosophy at Exeter University (HT
Arts and Letters Daily). In this article, Skidelsky laments the following “linguistic shift”:
No words are more typical of our moral culture than “inappropriate” and “unacceptable.” They seem bland, gentle even, yet they carry the full force of official power. When you hear them, you feel that you are being tied up with little pieces of soft string. Inappropriate and unacceptable began their modern careers in the 1980s as part of the jargon of political correctness. They have more or less replaced a number of older, more exact terms: coarse, tactless, vulgar, lewd. They encompass most of what would formerly have been called “improper” or “indecent.”…“Inappropriate” and “unacceptable” are the catchwords of a moralism that dare not speak its name. They hide all measure of righteous fury behind the mask of bureaucratic neutrality. For the sake of our own humanity, we should strike them from our vocabulary.
UPDATE: A very lively discussion of the meaning of the words in question (something I largely ignore) has broken out on Language Log
here)
This article makes four testable linguistic claims:
- The words inappropriate and unacceptable have increased in frequency over the last couple decades.
- This frequency increase is due to replacing other words: coarse, tactless, vulgar, lewd, improper, and indecent.
- These other words are “older”
- These other words are “more exact”
With a little investigation using entirely freely available online linguistics tools, we can easily fact check each of these claims. In the interest of time, I'll answer the first two together.
First and Second -- Has the frequency of inappropriate and unacceptable increased since the 1980s? & have they replaced the other words?
In order to quickly get some data, I took this to mean the frequency of the first two words have increased while the frequency of the other words have decreased since the 1980s (is this is an unfair interpretation?. In any case, that’s how I operationalized my methodology.). Thanks to Mark Davies excellent resource, the
TIME Corpus of American English (100 million words, 1923-2006, requires registration, but it's free) we can quickly get a snapshot of the frequency of each word’s usage for the last 9 decades (not bad, huh? Thanks Mark!!).
Caveat: raw frequency is a poor data point by itself. What we really need is a way to compare apples to apples and oranges to oranges, and the problem we have is different sized corpora for each decade. Fear not, Davies does this work for us. His handy dandy interface allows us to report frequency per million, thus giving us comparable frequencies across different decades.
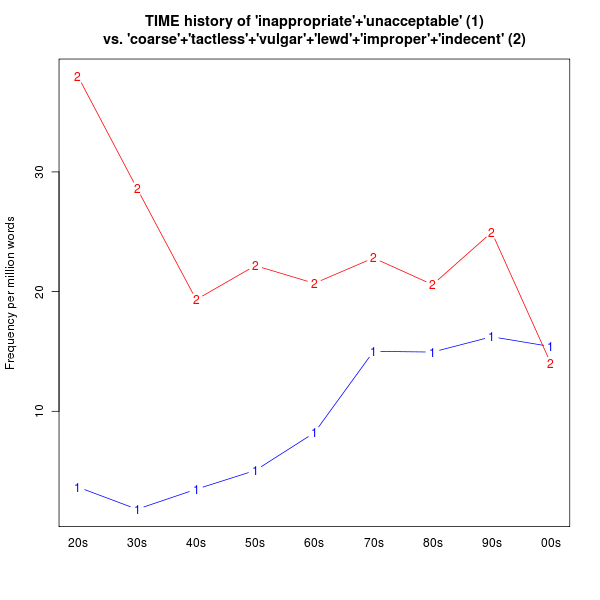
Using the TIME corpus, I discovered the frequency per million of each word per decade. Then I entered that data into a spread sheet. I used Excel 2007 to create a line graph of these frequencies.
Here's the relevant data:

And here's the graph:
 UPDATE
UPDATE (2hrs after original post): original graph was confusing (same graph, just confusing labels) so I fixed it.
What this shows us is that both
inappropriate and
unacceptable do in fact show a rise in frequency (consistent with Skidelsky's claim), but starting in the 1960s, not 1980s. However,
unacceptable shows a more recent dramatic decline, which is inconsistent with his claim.
Lewd actually made a bit of a comeback in the 1990s (thank you Mr. Clinton?), but has since dropped back (it's a bit of a jumpy word, isn't it?). The other words do seem to be falling off in usage, consistent with Skidelsky's claim. So the picture is not quite what Skidelsky thinks it is, though he does seem to be on to something.
UPDATE: See myl's plot of this same data (but grouping the words as Skidelsky does)
here which suggests that "
'coarse', 'tactless', 'vulgar' etc. declined until WWII and then stayed about the same, perhaps with an additional decline in past decade; while 'inappropriate' and 'unacceptable' rose gradually from the 1930s to 1970 or so, and then leveled off. " The plot does suggest that we could view the two groups as having roughly inverted frequency, somewhat conforming to Skidelsky's hunch.
Third -- Are these other four words “older”?
Unfortunately, as I am no longer affiliated with a university, therefore I have no access to the OED (I’ve decided not to pay the $295 for their individual subscription. Condemn me if you must). If anyone would care to look those up and post them in comments, I’d be happy to update. Most of these words have multiple senses and the question is, when did the most relevant sense enter usage? For that, the OED is most valuable. Again, you can do that work for me, or send me a check for $295.
However, a simple search of the Merriam Webster online dictionary gives us a quick answer:
unacceptable = 15th century
inappropriate = 1804
coarse = 14th century
tactless = circa 1847
vulgar = 14th century
lewd = 14th century
improper = 15th century
indecent = circa 1587
This data suggests these five words fall into roughly two groups:
A -- words that entered the language around the 19th century
- Set A = inappropriate, tactless
B -- words that entered the language around the 15-16 centuries
- Set B = unacceptable, coarse, vulgar, lewd, improper, indecent
This grouping does not conform to Skidelsky’s assumption that
inappropriate &
unacceptable fall together in a newer class and the others in an older class.
UPDATE: much thanks to commenter
panoptical who provides the following OED dates which appear to largely confirm the Merriam Webster dates, with the notable except of
lewd which dates back to Old English it seems...does have a certain Beowulf ring to it, doesn't it?
unacceptable: 1483
inappropriate: 1804
coarse: 1424
tactless: 1847
vulgar: 1391
lewd: c890
improper: 1531
indecent: 1563
Fourth -- Are the other words "more exact"?
Finding a way to empirically test this is a challenge I will take up in later post (you can see
Wordnet coming, can't you?). It will require teasing apart senses and relationships between senses (oh my, I wish I had the OED right now...).











{kind=link}